
This is the third in a series of several posts on how to do way more than you really need to with rofi. It's a neat little tool that does so many cool things. I don't have a set number of posts, and I don't have a set goal. I just want to share something I find useful.
This post looks at automatically updating modi lists. It also covers some intro awk stuff, so feel free to skip around.
Assumptions
I'm running Fedora 27. Most of the instructions are based on that OS. This will translate fairly well to other RHEL derivatives. The Debian ecosystem should also work fairly well, albeit with totally different package names. This probably won't work at all on Windows, and I have no intention of fixing that.
You're going to need a newer version of rofi, >=1.4. I'm currently running this:
$ rofi -version |
If you installed from source, you should be good to go.
Code
You can view the code related to this post under the post-03-scripting-modi-discovery tag.
Script modi Discovery
If you look at the man page or check rofi's help, you'll probably notice that not all the modis are enabled. You can also force the issue by attempting to -show a nonexistent modi:
$ rofi -show qqq |
A safer way to discover modi, on the off-chance you're running a qqq modi, is to check the tail end of rofi --help.
Using the default config, the currently enabled modi are as follows:
$ grep -E '\smodi:' $XDG_USER_CONFIG_DIR/rofi/config.rasi |
The definition is pretty simple. It's just a comma-separated list of modi inside a string. Since rofi gives provides a convenient list of accessible modi, we have two choices:
- manually pick desired
modiand manually update the config like a peasant, or - stream the whole thing directly from the help into the config.
Of course, you could probably finish #1 before you get done reading the following code breakdown, but where's the fun in that?
The first thing we have to do is parse the list of available modi. At the moment, it looks like help leads the list with Detected modi, prints modi name and active state, and finishes with an empty line. The rest of the help file isn't useful here. We're going to have to parse essentially the entire thing, since the pertinent help appears at the bottom. sed would be an okay solution, printing only the lines we're interested in and manipulating them. However, we'd have to pipe those results into something else to clean them up for use as a single-line string. awk, on the other hand, will let us parse the file and manipulate the return as needed.
Available modi
To start, let's declare a list of modi and a flag that can be used to determine whether or not the list of modi has started. awk's BEGIN section is only run once, at the beginning of the input.
available-modi-parser snippet |
|
1 2 3 4 |
BEGIN { |
We'll need some way to let awk know when we should start grabbing. next lets us skip to the next record without processing anything else.
available-modi-parser snippet |
|
1 2 3 4 |
/Detected modi/ { |
If we're not grabbing, there's no reason to process any of the other conditionals.
available-modi-parser snippet |
|
1 2 3 |
!grabbing { |
Once we are grabbing, we should stop when we hit a line with no fields. The NF magic variable counts the number of fields per record. The exit command will shoot us straight to the END of the awk script, skipping any remaining records.
available-modi-parser snippet |
|
1 2 3 |
grabbing && !NF { |
If we are grabbing and we have records, they're going to look something like this:
* +window |
That means the numbered inputs look something like this:
$0: * +window |
So we want to consume $2, except we don't want +. gsub will replace any instance of a pattern in the record. String concatenation you should already understand; awk just glues things together without the need for extra operators.
available-modi-parser snippet |
|
1 2 3 4 |
grabbing { |
Finally, at the tail end of the script, we want to print what we've found. Similar to the BEGIN block, the END block is run once, after all the records are processed (or exit is called). gensub takes a pattern, a replacement, the method, and input string. If you'll notice above, we're going to have an extra trailing comma at the end of modi.
available-modi-parser snippet |
|
1 2 3 |
END { |
At this point, we could do something like this:
$ rofi --help \ |
However, that means we'd have to manually copy that and manually paste it into out config. Like a peasant. Or we could stream it. Guess what I want to do.
We have a small problem. (Or rather, I have a small problem, possibly related to my lack of bash knowledge.) awk dumps to /dev/stdout. That means consuming awk has to be done in a subshell, which is kinda boring, or sourced (sorta), which is exotic (AND POTENTIALLY VERY DANGEROUS). I personally prefer creating variables, rather than throwing together a hot mess of nested subshells. Coming from JavaScript, I'm very wary of callback hell.
We can easily modify what we've written so far to dump a variable instead of a simple string.
available-modi-parser snippet |
|
1 2 3 |
END { |
$ rofi --help \ |
Consuming this is as simple as sourceing the pipe.
$ rofi --help \ |
Updating the Config File
To edit the config, we'll have to parse the existing config line-by-line and update the desired values. sed is the go-to, but, once again, awk offers a couple of features that are useful here:
bashvariable expansion is much easier (i.e. less messy) withawk, and- manipulating multiple things at the same time is a bit easier.
We'll need to figure out which config option we want to modify:
$ cat $XDG_CONFIG_HOME/rofi/config.rasi | grep modi |
-show-able modi
The first thing we want to do is limit ourselves to the -show-able modi config:
$ cat $XDG_CONFIG_HOME/rofi/config.rasi \ |
Since we've built a desired list of modi, $DISCOVERED_MODI, we can simply replace the line. We can set variables in awk via -v By default, the file uses tab characters (\t) to align entries, so we'll need to lead with that.
$ cat $XDG_CONFIG_HOME/rofi/config.rasi \ |
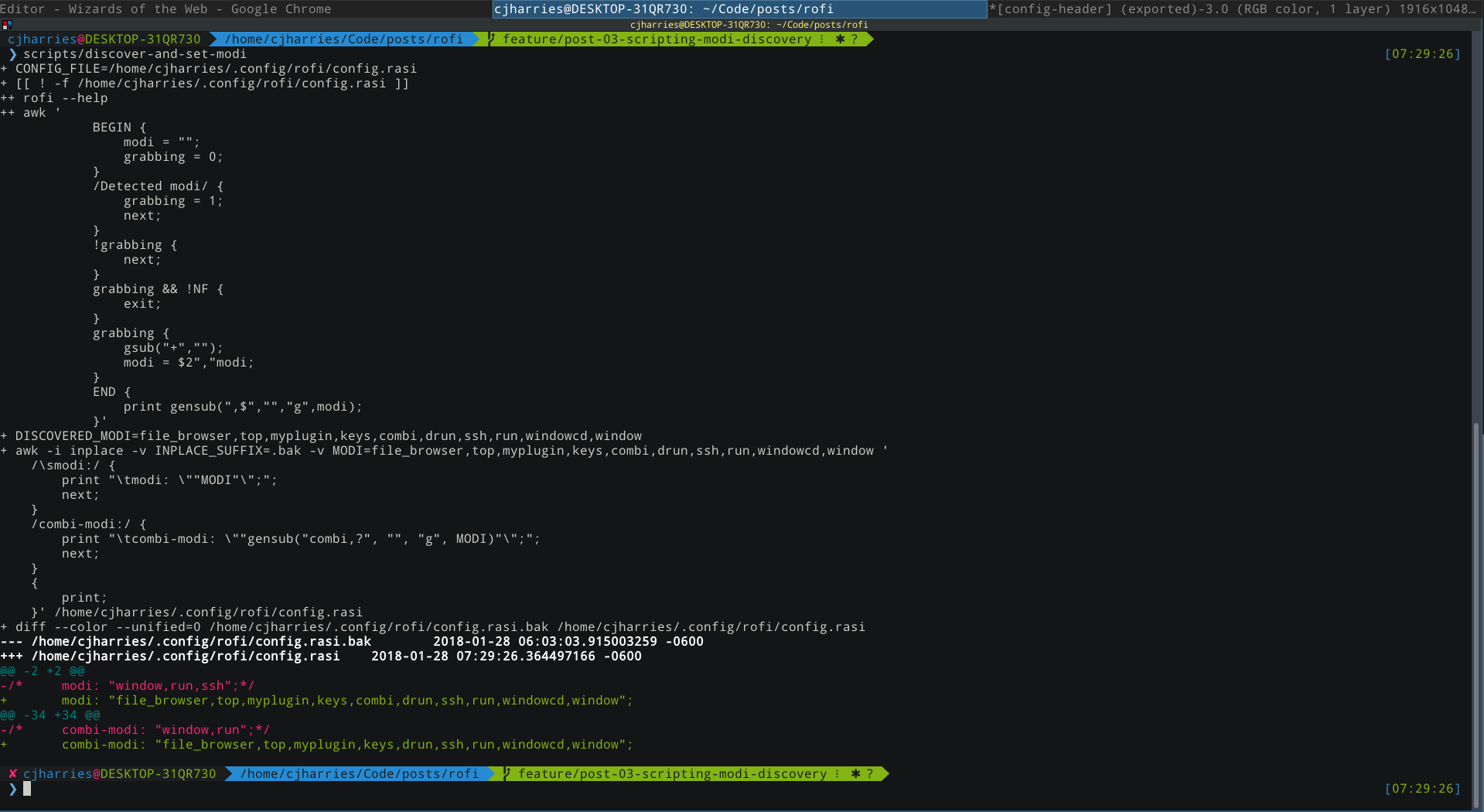
Provided awk is >=4.1, we can edit streams inplace. We'll need to modify the script to print any unmatched lines as well.
$ awk \ |
--- $XDG_USER_CONFIG_DIR/rofi/config.rasi.bak |
combi modi
This process is almost identical to -show-able modi, so I'll skip the awk breakdown. The combi modi combines multiple modi into a single instance. This allows us to group multiple modes together by default.
The simplest solution would be to repeat exactly what we did above.
$ awk \ |
--- $XDG_USER_CONFIG_DIR/rofi/config.rasi.bak |
However, this causes a fairly abrupt segfault.
$ rofi -show combi |
The problem is straight-forward to debug. combi loads the provided list of modi. Since combi contains itself, it tries to load itself. Ad infinitum. It's also straight-forward to fix.
$ awk \ |
--- $XDG_USER_CONFIG_DIR/rofi/config.rasi.bak |
All the modi
I've combined everything into a script and a glob. The first uses a subshell to discover available modi whereas the second pipes and sources. The result should be the same.
Shell Script
|
discover-and-set-modi
|
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
#!/bin/bash |
glob
This can be used as copypasta. Probably.
$ rofi --help \ |
--- $XDG_USER_CONFIG_DIR/rofi/config.rasi.bak |